For each and every query, Google retrieves the most relevant webpage from its database.
It’s a goal of every SEO copywriter that his page becomes the best of all the indexed webpages and get visible on the first page of Google.
You always try your best to understand that what Google Bots are taking into their account while judging your content.
You sometimes might get confused while understanding the ranking factors of the content.
Whether you are targeting the right keywords or not? How frequent should you add your keywords? Is it looking spammy?
But do you ACTUALLY know the Most Important technique Google Bots are using to judge content’s quality?
Most of you, don’t!
The Most Important and primary ranking algorithm is tf-idf.
It was introduced in the 1970s and uses the presence, number of occurrences, and their locations to generate a statistical data on the importance of a term in the document.
The terms that are appearing in a small group of documents will have higher tf-idf weight than common stop words like “the” and “this”.

Mathematically, it is a product of 2 important stats, i.e., term frequency (tf) and inverse document frequency (idf).
Let’s head over to these 2 very important factors and understand them in detail to absorb the concept of tf-idf.
And don’t feel intimidated by these nerdy terminologies.
These are quite simple!
Wikipedia explained the term tf-idf in an awesome way: In information retrieval, tf-idf, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in information retrieval and text mining.
Term Frequency
The term frequency tft,d of a term in the document is the number of times t occurs in d. tft,d is required while computing query document match score.
Consider you want to determine the most relevant document to the query “the black ring” from a set of text documents.
The best way to do is by eliminating the documents that do not contain all the 3 words.
But this will still leave many documents.
So to further distinguish, we have to count the number of times each word is coming in a document and then sum up them together.
This sum is what we call “term frequency”.
There is also a preferred Mathematical formula for the calculation of term frequency :
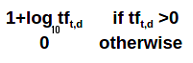
Here, tft,d = term frequency of term t in document d
Please note that here log is used to dampen the effect of tft,d.
I have also added 1 to log tft,d because when tf is equal to 1, the log(1) is zero.
Adding one will distinguish wt,d when tf=0 and tf=1.
Easy, right?
Inverse Document Frequency
Inverse Document Frequency is the measure of the uniqueness of a term.
It shows whether a term is common or rare in the document.
In the computation of tf, we have considered all the terms important.
Although you all know that few terms like “the”, “of”, and “a” appear a lot of times in the document but are having little importance.
Hence, we need to lower the weight of frequent coming terms and scaling up the rare ones.
Let’s understand this with an example:
Consider that total number of documents are 10,000,000.
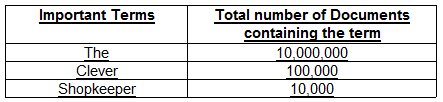
According to the above example, “The” appears in every document.
But it shows that it provides no value in the document as it is present in every document.
If we look at “Shopkeeper”, it is present in 10,000 documents.
Clearly, this information tells us that this phrase is having importance in the documents in which it is present.
Mathematically, it looks like this:
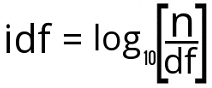
For each query term, we will divide the a total number of documents in the document sets by total number of documents containing the query term.
This calculation will result in big value!
So, to dampen this, we have used log base 10 here to make it look less complicated and sensible.
Let’s again look at the example:
Consider, a total number of documents are 10,000,000.
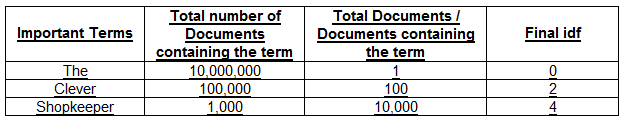
So, we are giving importance to the term which is rare and most SIGNIFICANT too!
Combining the above 2 metrics will make a powerful technique, i.e., tf-idf.
Term Frequency-Inverse Document Frequency (tf-idf)
Term Frequency-Inverse Document Frequency is a numeric statistical data which is used to express how important a term is in a document.
It increases with the frequency of query term within the document and is the best-known weighting scheme for information retrieval.
It is used by Search Engines to score and rank a document with regards to the user query.
It is also successfully used for filtration of stop-words from the documents.
The words with high tf-idf values shows that they are having a strong relationship with the document it is appearing in.
The tf-idf weight of a term is the product of its term frequency and inverse document frequency. Mathematically, it is represented as:
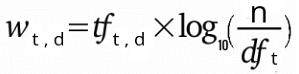 Its alternative names are tf*idf & tf.idf
Its alternative names are tf*idf & tf.idf
Continuing the example of idf, let’s calculate their tf-idf:

As you can see, the tf-idf is calculated for above-mentioned terms.
Thus, the rare term has the high idf and the frequent term is likely to have low idf.
This type of weighing scheme is the best one and increases with the number of occurrences in the document.
Advantages of tf-idf
- Efficient and simple for matching words of query terms with the document’s content
- Returns highly relevant documents for a particular query
- Uses basic metric to evaluate descriptive terms in a document
- Ideal for becoming foundation of more complicated algorithms
- Similarity between 2 documents can be found easily.
tf-idf is still the standard algorithm although many new algorithms have come up for Query retrieval.
This algorithm will help you to produce unique content and keep you away from the penalty of keyword stuffing.
Search Engines use the same formulas for ranking your pages and domain, so make sure to search the best keywords for use and generate and analyze your things by tf-idf method.
The above detailed explanation of tf-idf will help you in creating distinct and potentially high quality content with the correct number of targeted keywords placed in the content.
What’s your thoughts on tf-idf? Did you find some other great technique of information retrieval that you want to share?
I’ll love to hear from you, drop a comment below!
Don’t forget to share it with your mates for helping them too.
About The Writer:
I’m a professional Digital Marketing Consultant. However, blog writing is my passion and have been writing for the last 6 years on various niche and industries. Apart from blog writing, I am Google Adwords Certified Member. In my free time, I love to meet new people at new places.